品丁真文学,享颓废人生。本篇教程开始之前,请看一段VCR——丁真颓废文学_哔哩哔哩_bilibili
AI发展到现在,这种复制别人声音的项目已经很成熟了,稍微动动小手就可以做一个很有意思的视频(Ps. 看B站挺火才以丁真做个示范,如有侵权请联系我删除)。今天这篇就教一下如何本地训练模型来克隆别人或者自己的声音,本次项目使用docker部署,省去了好多依赖配置,基本小白也能部署成功。
GPT-SoVITS
GPT-SoVITS是一个开源的文本到语音(TTS)项目,由RVC变声器的创始人(GitHub昵称为RVC-Boss)与AI音色转换技术专家Rcell合作开发。项目目前已经快20K start了,作者自己部署使用了一番,部署简单且使用体验和产出的结果都挺不错,可以一试。
Github地址:GPT-SoVITS/docs/cn/README.md at main · RVC-Boss/GPT-SoVITS · GitHub
不多BB,直接进入正题。
前提准备
训练模型的时候主要依赖内存和显卡,我这里是16G内存和N卡的1650,已经很拉了但跑起来除了有点慢还是很顺畅的(必须是N卡)。
其次就是本机上要装docker和docker-compose,不会装的话windows请看我之前写的教程——windows安装docker和docker-compose | 爱加班的小刘 (xiaoliu.life)
本地部署
这里我是用docker部署到本地,相较于裸机部署的话使用docker在配置的时候有点坑,下文会重点介绍。
自己在电脑上创建一个GPT-SoVITS目录,然后进到里面新建三个目录logs、output和SoVITS_weights。

在当前目录下打开cmd窗口,使用下面docker命令来启动部署服务。为了后面不出错,最好不要修改命令里面的参数。
1 |
docker run --rm -it --gpus=all --env=is_half=False --volume=.\output:/workspace/output --volume=.\logs:/workspace/logs --volume=.\SoVITS_weights:/workspace/SoVITS_weights --workdir=/workspace -p 9880:9880 -p 9871:9871 -p 9872:9872 -p 9873:9873 -p 9874:9874 --shm-size="16G" -d breakstring/gpt-sovits:latest |
项目需要拉取的docker镜像差不多有10G,而且还是从国外拉,所以速度很慢耐心等着吧。
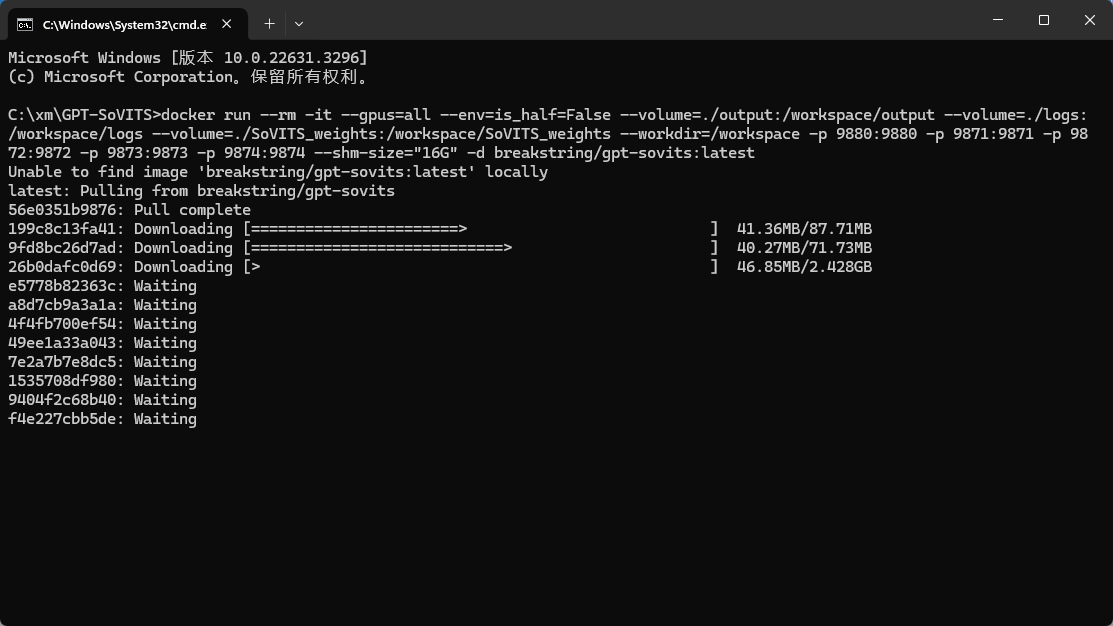
等待容器下载起来后,浏览器访问本机的http://127.0.0.1:9874,能成功打开就说明启动成功了。
训练模型
这里以丁真的声音为例,需要先训练丁真的声音模型。
人声分离
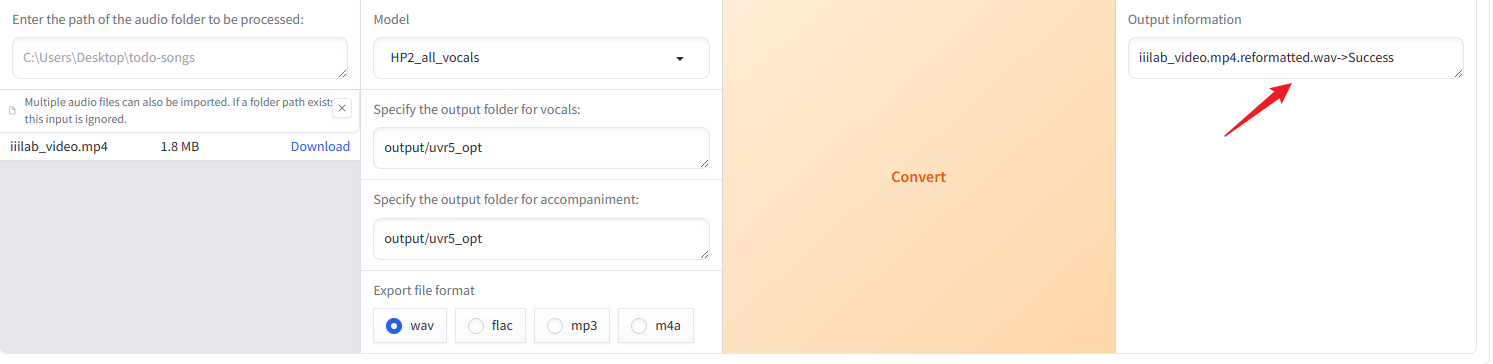
这一步操作是使用UVR5(一个处理声音的软件)提取出干净的人声,把Open UVR5-WebUI这个选项勾上。

然后浏览器打开http://127.0.0.1:9873来进行人声分离,依次跟着如下步骤操作:

等待处理完成。
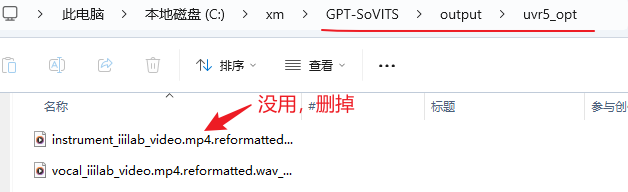
现在切换到我们前面第一步新建的目录里GPT-SoVITS\output\uvr5_opt,会有两个人声文件。instrument开头的这个删掉,没啥用,只保留vocal这个文件。
再使用另一个模型处理一下分离出来的人声音,这里就有个坑了。
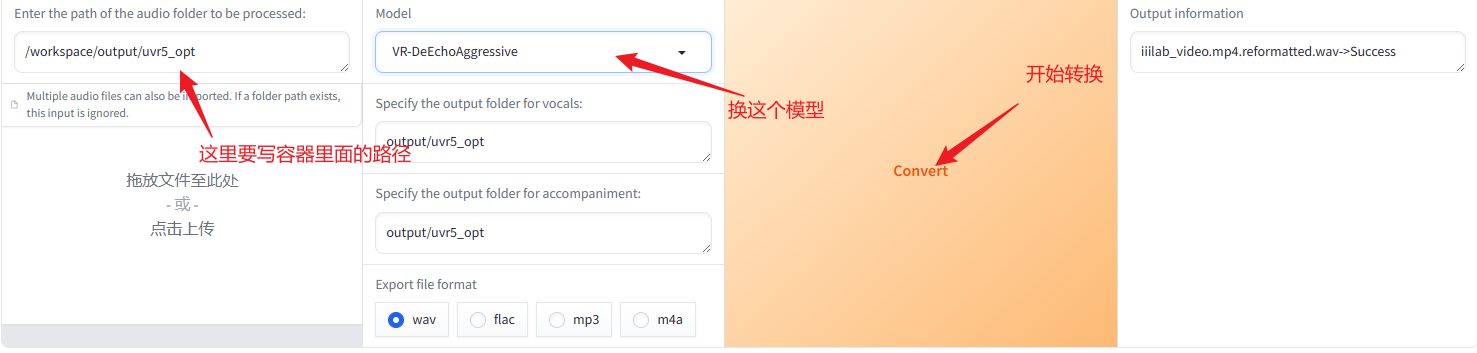
这里的人声要写容器里面的路径,不要写自己本机路径,会找不到的。如果前面都是跟着改的话,直接填这个/workspace/output/uvr5_opt路径即可。模型的话要用VR-DeEchoAggressive。
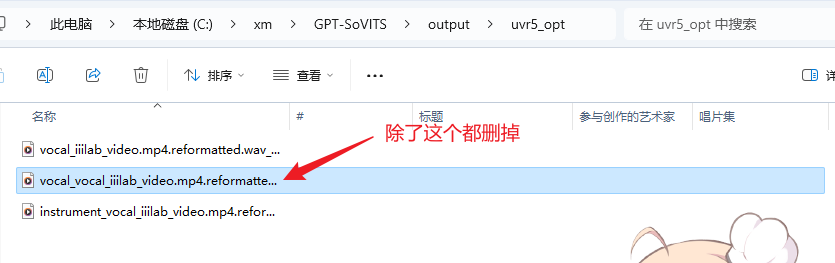
等待运行结束后同样会生成两个文件,把除了vocal_vocal这个开头的文件,其他都删掉。
音频切片
这一步是把音频切成一小段,防止一次性处理太多把显存爆掉。
切到http://127.0.0.1:9874,音频路径写/workspace/output/uvr5_opt。路径地址是上一步分离的音频路径,同样是填docker里面的路径。
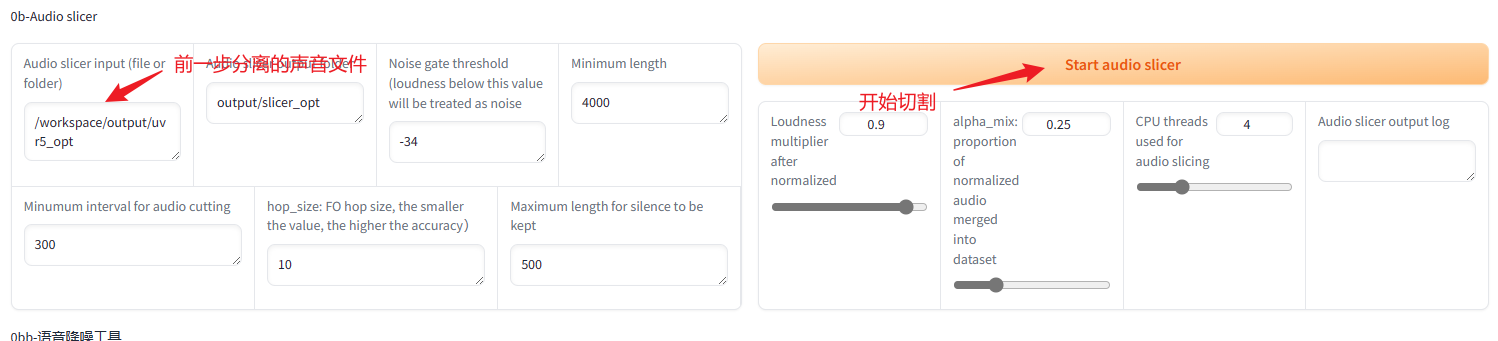
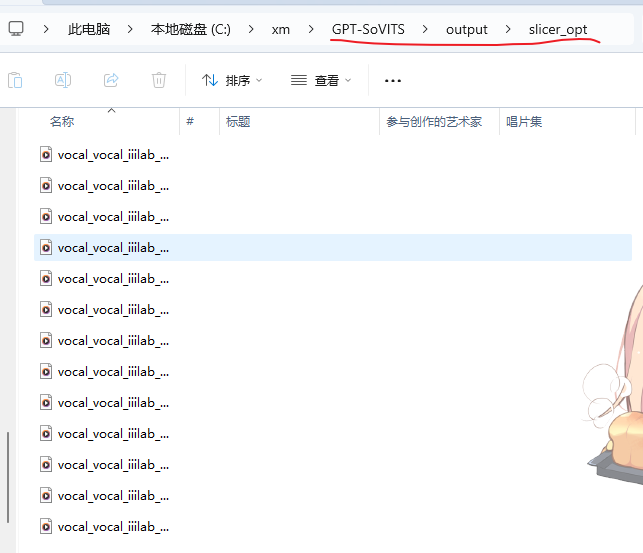
等待切割完成,切完的文件在GPT-SoVITS\output\slicer_opt下。
标记
同样是http://127.0.0.1:9874这个路径,滑到最下边准备开始打标,
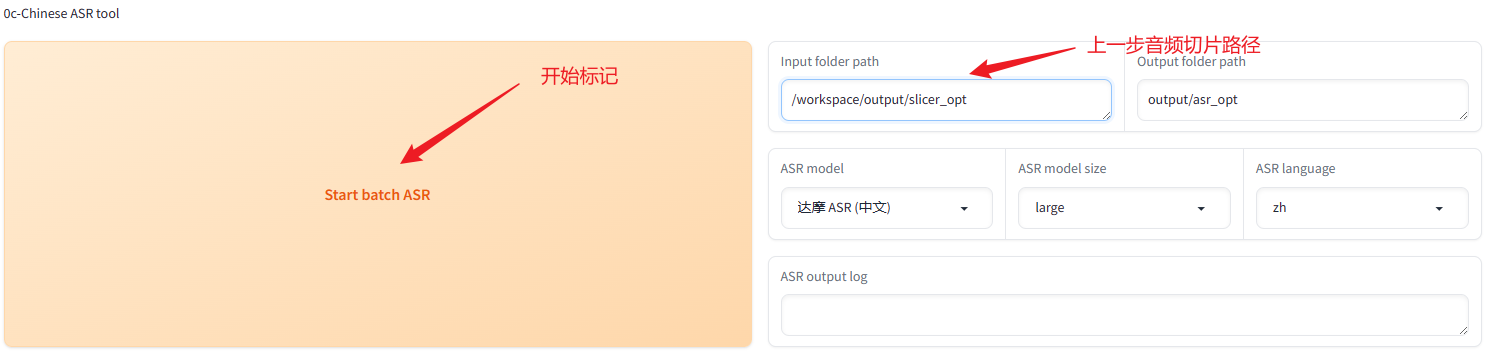
同样是docker里面的路径,这里填/workspace/output/slicer_opt
等待标记完成,生成的文件在/workspace/output/asr_opt路径下
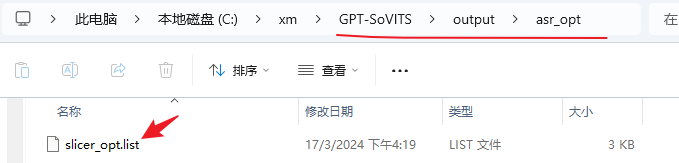
OK,准备工作已经完成,接下来就是紧张刺激的训练步骤了。

按照图中顺序一步步来,第二步文件路径是/workspace/output/asr_opt/slicer_opt.list,可能文件名称不一样需要改一下。第三步文件夹路径是/workspace/output/slicer_opt,这个不需要改。
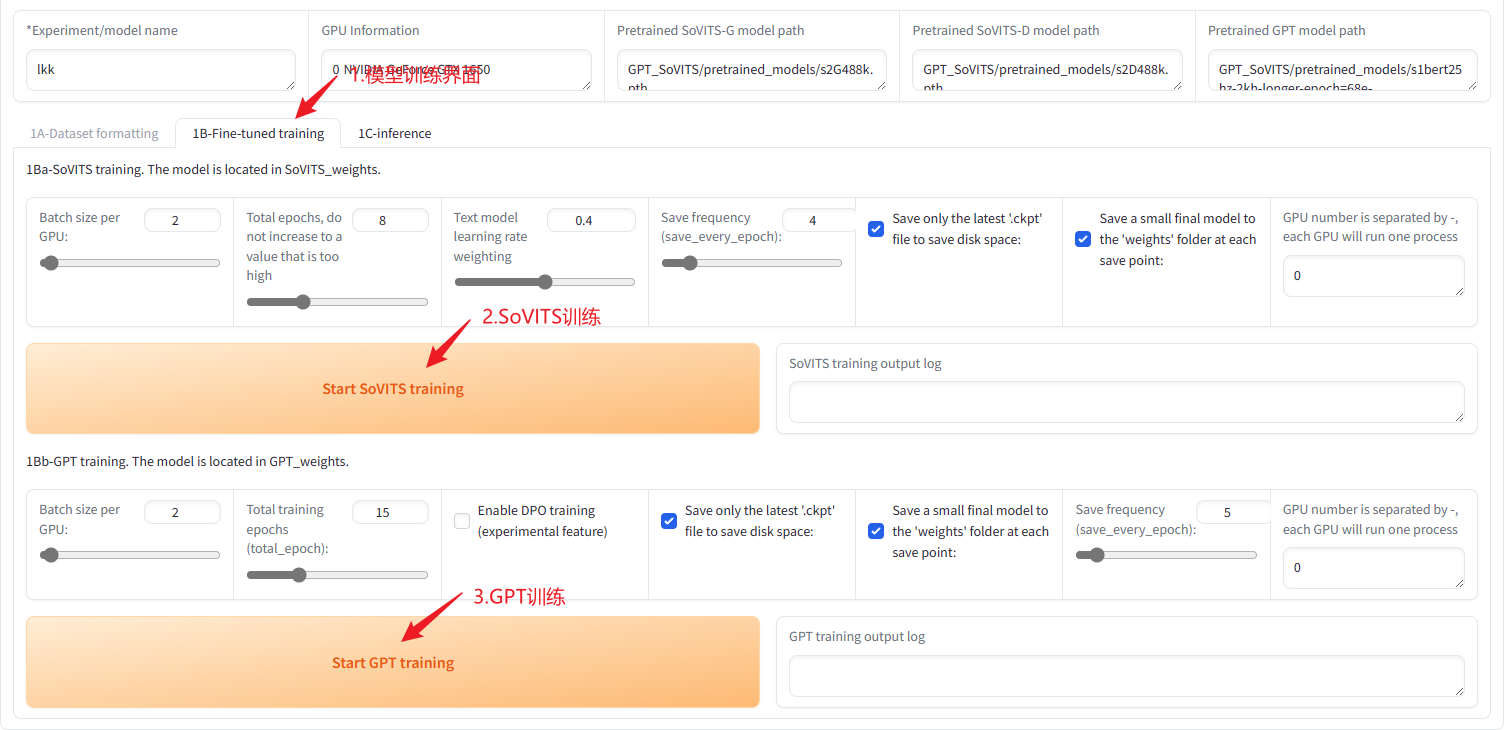
之后切换选项卡到1B-Fine-tuned training,其他配置都用默认即可。先训练SoVITS再训练GPT,切记要等待一个训练完后再训练另一个。
显卡不行的话训练时间会很长,要有耐心等待。训练完成后模型会生成在GPT-SoVITS\SoVITS_weights目录下。
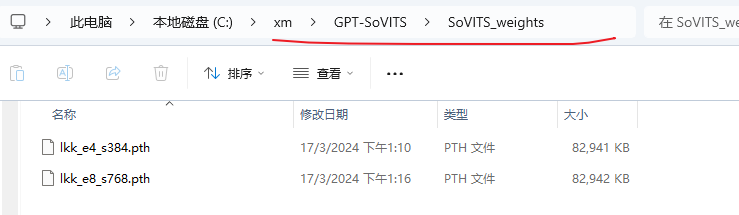
音频生成
写了这么久终于要到最后一步了,访问http://127.0.0.1:9874,把WEBUI打开。
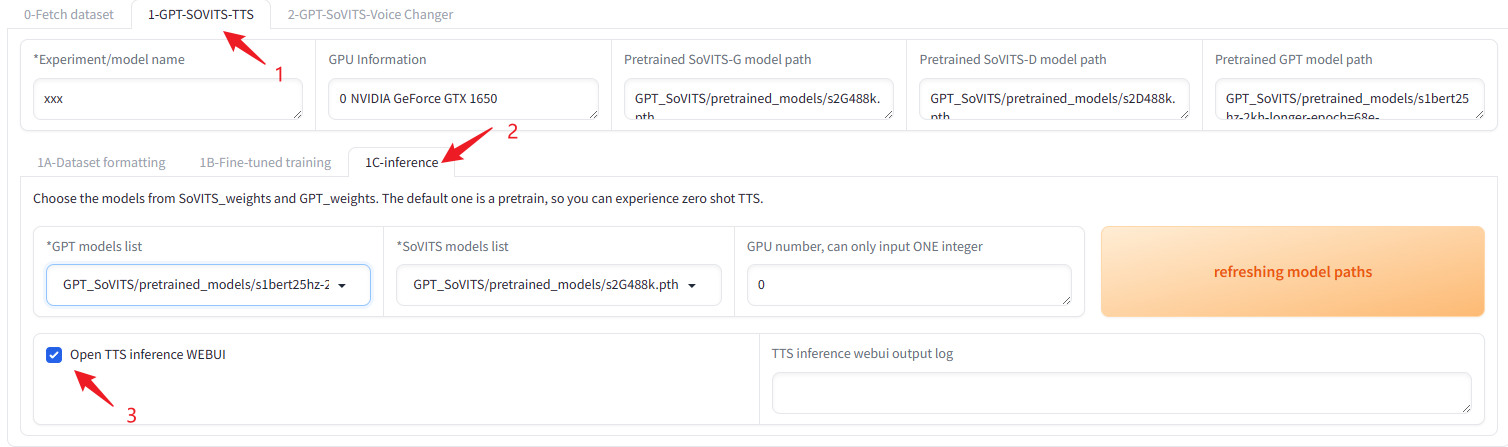
然后访问http://127.0.0.1:9872,这个就是合成声音的界面了。
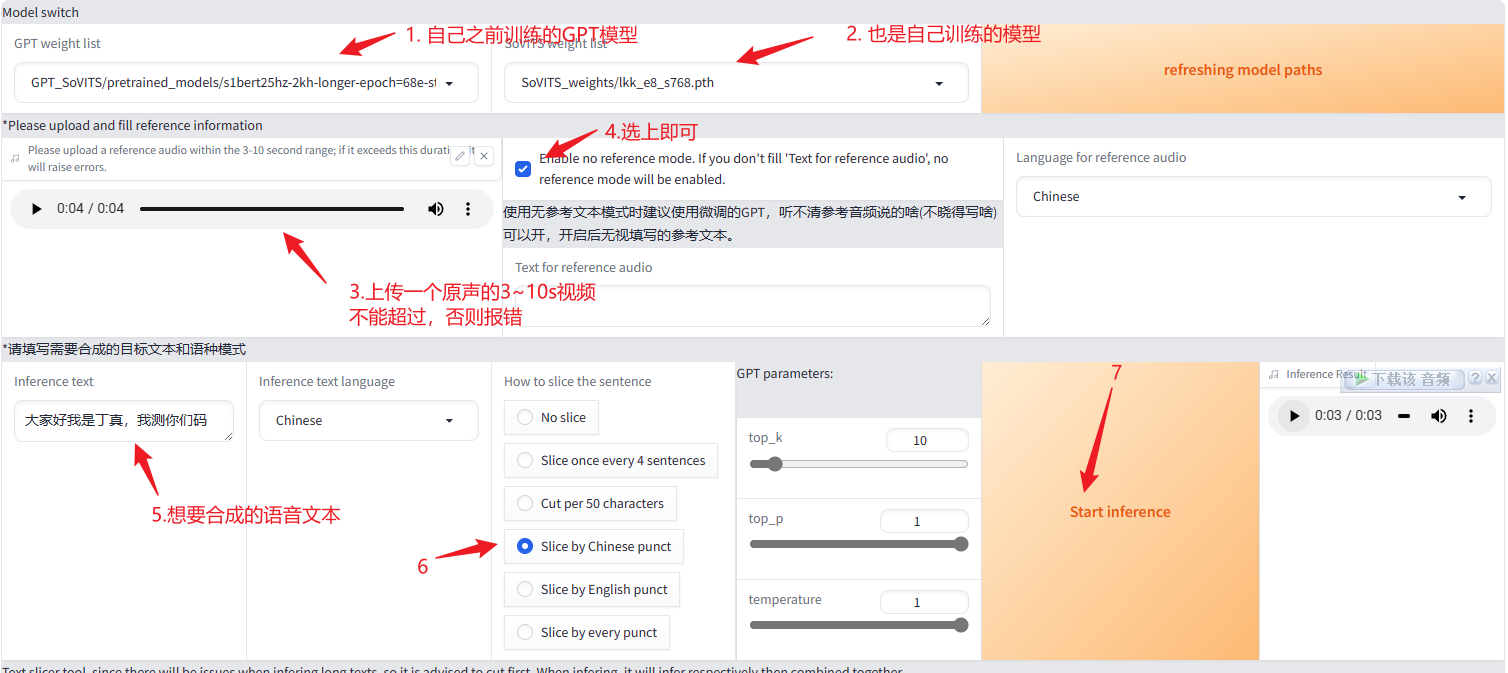
根据上图步骤一点点来,其中第三步尤其注意只能上传3~10s的音频,超过的话会报错。
这个语音合成就很快了,几秒钟即可。
闲聊
见过凌晨三点的天津么,昨天我就见到了,nnd困死。
相关文章

