上周介绍了爬虫爬小说,今天浅爬一下图片吧。
今天爬的图片网站是https://wallhaven.cc/,之前有篇推荐壁纸网站的文章,这个网站就在那里面。
这个网站比较友好,不像之前的小说网站—-笔趣阁,每个标签内还有乱码,增加你处理的难度。
所以此次使用xpath分析,不用re了。
和之前一样,三步走:
- f12观察页面源码,找到图片的网址
- 确定思路(这次简单,不需要跳转很多的页面,就需跳转一下)
- 开始实践
f12分析页面源码
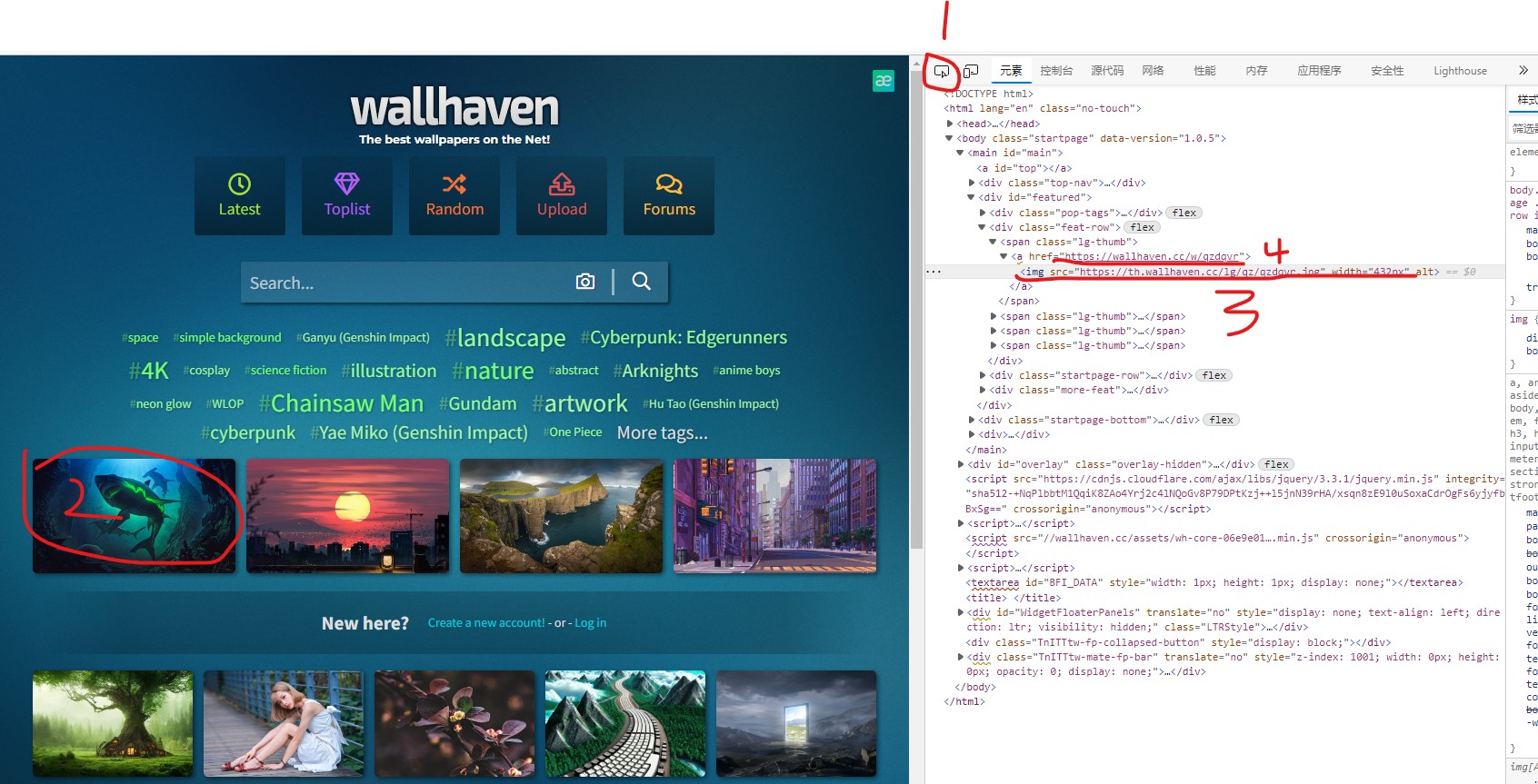
f12查看页面源码。

先点一下1号地方,随便找个图片点一下(比如2号圈主的地方),看图片的链接是哪里。3号地方就是图片链接地址,4号是点击图片后的跳转地址。
点击3号地方的链接,发现那只是个缩略图,而我们想要1080P(甚至4K)。点击图片(也就是4号所对应的链接)跳转到下一个页面,找到原始图片的链接。
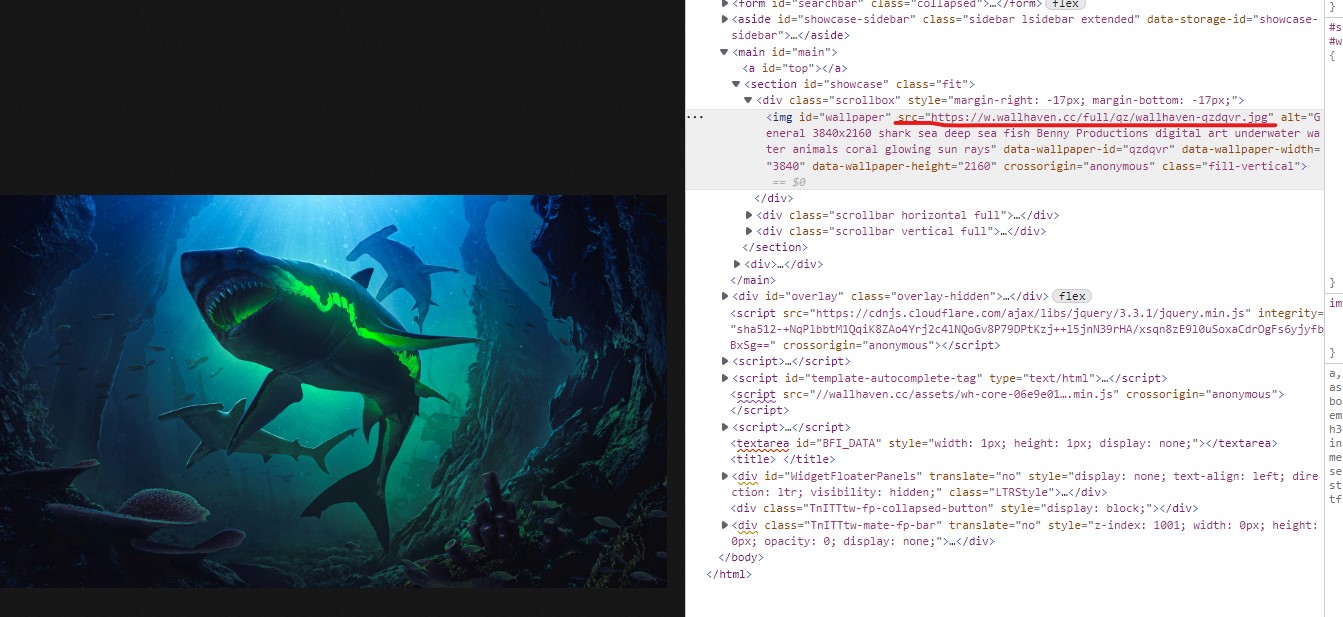
跳转到下一个页面后,f12查看图片所对应的位置,找到了原始图片的链接,即红线对应的src属性。
现在就简单了,首先获取主页所有的4号链接,跳转过去后找到原始图片的链接,下载到本地即可。
关键函数
1
2
3
4
5
6
7
8
9
10
|
def get_page_url(url):
try:
urlhtml = requests.get(url,headers)
urlhtml.encoding = "utf-8"
htmlcode = urlhtml.content
html = etree.HTML(htmlcode)
text = html.xpath('//div[@class="feat-row"]/span/a/@href')
except:
text = 'error'
return text
|
根据函数名字不难猜出来,这是获取主页点击图片后跳转页面的链接(即第一步的4号链接)。
咳咳,按照我原本写代码的风格,此时函数名应该叫def a(),后来被我的指导员(之前文章提到的南哥)揍了几次后就改了。
简单说一下函数中xpath用法吧,其他应该挺好理解。
“//div[@class=”feat-row”]/span/a/@href”中的”//div[@class=”feat-row”]“代表匹配文中所有的class = feat-row的div标签,之后就是找这个标签下的span标签,再找a标签,最后找a标签里面的href属性,一步步就找到我们需要的链接了。
1
2
3
4
5
|
def get_picture_url(picture):
picture_html = picture.content
picture_html1 = etree.HTML(picture_html)
picture_url = picture_html1.xpath('//section[@id = "showcase"]/div/img/@src')
return picture_url
|
看名字就知道了,要找到原始图片的链接。
和上面函数语法基本一样,不多解释。值得注意的一点,返回的picture_url是一个列表,而我们只需要第一个(列表里也只有一个),所以最后用的时候要加[0],即picture_url[0]。
1
2
3
4
5
|
def get_picture_name(picture):
picture_html = picture.content
picture_html1 = etree.HTML(picture_html)
picture_name = picture_html1.xpath('//section[@id = "showcase"]/div/img/@alt')
return picture_name
|
获取图片对应的名字。你也可以不用这个,自己给每个图片起名,我是懒得起了。
同样,返回的是列表,也是只需要第一个,别忘了加[0]。
具体代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
import requests
from lxml import etree
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'
}
def get_page_url(url):
try:
urlhtml = requests.get(url,headers)
urlhtml.encoding = "utf-8"
htmlcode = urlhtml.content
html = etree.HTML(htmlcode)
text = html.xpath('//div[@class="feat-row"]/span/a/@href')
except:
text = 'error'
return text
def get_picture_url(picture):
picture_html = picture.content
picture_html1 = etree.HTML(picture_html)
picture_url = picture_html1.xpath('//section[@id = "showcase"]/div/img/@src')
return picture_url
def get_picture_name(picture):
picture_html = picture.content
picture_html1 = etree.HTML(picture_html)
picture_name = picture_html1.xpath('//section[@id = "showcase"]/div/img/@alt')
return picture_name
if __name__ == '__main__':
url = get_page_url('https://wallhaven.cc/')
a = ["1","2","3"]
b=0
for i in url:
picture_page = requests.get(i, headers)
picture_page.encoding = 'utf-8'
picture_name = get_picture_name(picture_page)
picture_url = get_picture_url(picture_page)
f = open(picture_name[0]+'.jpg','wb+')
f.write(requests.get(picture_url[0],headers).content)
f.close()
print('打印完成一张')
|
对了,最后写入图片的时候open模式选择wb+,写入二进制,别用a+。
运行状态
每下载完一张图片就会在控制台打印一下。
由于网站在国外且图片清晰度过高,运行可能会很慢。
文件保存路径是你当前项目路径下。
学习即可,请不要大并发爬别人网站,造成别人服务器瘫痪跟我无关。