学习归来,分享下如何多线程爬小说资源。本期的受害者是笔趣阁,选它的原因,一方面是它基本没做什么防爬,另一方面盗版网站爬了应该没多大关系,想尝试的小伙伴建议点到为止,出了事小刘不负责!!!
- 查看页面源代码,找到每一章链接构成
- 确定好爬取思路
- 把你的逻辑用代码表现出来
分析页面构成
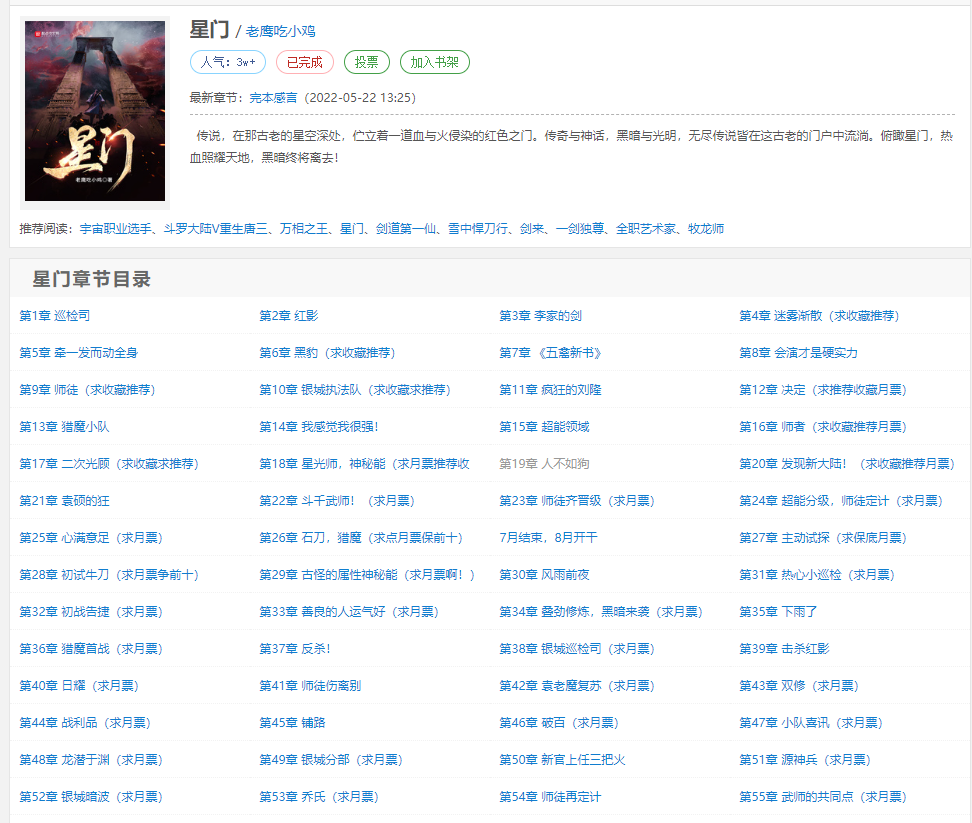
今天爬的小说叫”星门”,刚完结没多久吧。

浏览器按“F12”查看页面代码,主要找到每一章节的链接。F12查看源代码可能并不好看,这里我直接下载下来了。
1
2
3
4
5
6
7
8
9
10
11
|
def get_htmlcode(url):
try:
urlhtml = requests.get(url)
htmlcode = urlhtml.content
path = open('Txt/html1.txt','wb')
path.write(htmlcode)
path.close()
except:
htmlcode = 'error'
|
上面函数把这个网页的html源码下载到当前项目路径Txt目录下的html1.txt中
可以看到页面章节链接是
1
|
<dd><a href="56529084.html">第19章 人不如狗</a></dd>
|
格式,我们想要获取的只有56529084.html,之后再与https://www.bbiquge.net/book/133318/拼接,就能访问到第19章了。
进入到19章,查看页面源码可以看到每一行小说都是
1
|
<br /><br /> 很好,听到了自己想要听的话。
|
这种格式,那么我们就可以根据这个规律匹配出来每一行小说保存到我们本地。
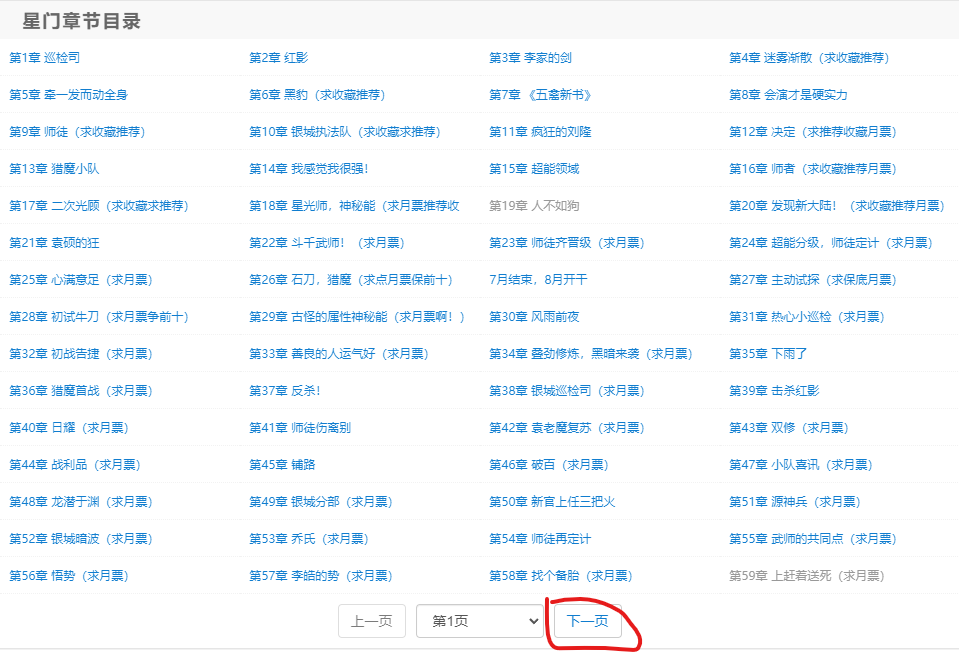
由于这页只有57章,所以我们要获取下一页的链接用来转到第二页,即上面圈住的/book/133318/index_2.html,与https://www.bbiquge.net拼接就可以访问到下一页了。
整体思路
首先当然是来到整篇小说列表第一页
- 把整个页面每一章的链接内的小说都爬一遍,然后访问下一页。
- 重复进行第一步,直到小说的最后一页。本次共需重复第一步17次,即有17页。
关键代码详解
代码实现挺简单的,主要涉及网页请求、正则匹配和线程池这三方面。
因为每一章小说是分别存在不同的txt文件中,所以不用关心多线程会导致章节错乱。
1
2
3
4
5
6
7
8
9
10
11
|
def get_htmlcode(url):
try:
urlhtml = requests.get(url)
htmlcode = urlhtml.content
except:
htmlcode = 'error'
return htmlcode
|
这个函数用来获取页面的源代码,返回给其他函数进行处理。
1
2
3
4
5
6
|
def get_page_list(htmlcode):
reg = '<dd><a href="(.+?)">'
reg_msg = re.compile(reg)
list_all = reg_msg.findall(str(htmlcode))
return list_all
|
这个函数主要用来获取当前页面所有章节的链接,利用正则匹配的方法。
返回的list_all存放的是当前页面所有链接构成的链表。
可以尝试输出一下list_all,会得到下面的结果
1
2
3
4
5
6
|
def get_subject(htmlcode):
reg = '<title>(.+?)</title>'
reg_msg = re.compile(reg)
subject = reg_msg.findall(htmlcode.decode('gbk'))
return subject
|
获取本章小说的名字比如“第一章巡检司”,之后写入到小说第一行。
1
2
3
4
5
6
7
|
def get_novel(htmlcode):
htmldecode = htmlcode.decode('gbk')
reg = '<br /><br /> (.+?)<'
reg_msg = re.compile(reg)
novel = reg_msg.findall(htmldecode)
return novel
|
也是利用正则匹配获取到每一行小说的内容,存在novel列表中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def get_novel_all(chapter_url):
Htmlcode_chapter_list = get_htmlcode(chapter_url)
if Htmlcode_chapter_list == 'error':
print('~~~~~~~~~~~~~17K小说地址出错了:%s,请稍后再试~~~~~~~~~~~~~'%chapter_url)
else:
zjmc = get_subject(Htmlcode_chapter_list)
path = open('星门/' + zjmc[0] + '.txt', 'a+', encoding='utf-8')
path.write(zjmc[0])
path.write('\n')
novl = get_novel(Htmlcode_chapter_list)
for i in novl:
path.write(i)
path.write('\n')
print("当前章节打印完成")
path.close()
|
这个函数调用上面三个函数,真正写入一章小说到本地文件里。
1
2
3
4
5
6
7
8
|
def get_next_list(htmlcode):
reg = '</option></select><span class="input-group-btn"><a class="btn btn-default" href="(.+?)">下一页'
reg_msg = re.compile(reg)
next_list = reg_msg.findall(htmlcode.decode('gbk'))
return next_list
|
本页小说章节链接遍历完后就会获取下一页链接并进行访问下一页的所有章节,直到所有章节访问完成。
具体代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
import os
import requests
import re
from concurrent.futures import ThreadPoolExecutor
def get_htmlcode(url):
try:
urlhtml = requests.get(url)
htmlcode = urlhtml.content
except:
htmlcode = 'error'
return htmlcode
def get_page_list(htmlcode):
reg = '<dd><a href="(.+?)">'
reg_msg = re.compile(reg)
list_all = reg_msg.findall(str(htmlcode))
return list_all
def get_next_list(htmlcode):
reg = '</option></select><span class="input-group-btn"><a class="btn btn-default" href="(.+?)">下一页'
reg_msg = re.compile(reg)
next_list = reg_msg.findall(htmlcode.decode('gbk'))
return next_list
def get_subject(htmlcode):
reg = '<title>(.+?)</title>'
reg_msg = re.compile(reg)
subject = reg_msg.findall(htmlcode.decode('gbk'))
return subject
def get_novel(htmlcode):
htmldecode = htmlcode.decode('gbk')
reg = '<br /><br /> (.+?)<'
reg_msg = re.compile(reg)
novel = reg_msg.findall(htmldecode)
return novel
def get_novel_all(chapter_url):
Htmlcode_chapter_list = get_htmlcode(chapter_url)
if Htmlcode_chapter_list == 'error':
print('~~~~~~~~~~~~~小说地址出错了:%s,请稍后再试~~~~~~~~~~~~~'%chapter_url)
else:
zjmc = get_subject(Htmlcode_chapter_list)
path = open('星门/' + zjmc[0] + '.txt', 'a+', encoding='utf-8')
path.write(zjmc[0])
path.write('\n')
novl = get_novel(Htmlcode_chapter_list)
for i in novl:
path.write(i)
path.write('\n')
print("当前章节打印完成")
path.close()
url_list = 'https://www.bbiquge.net/book/133318/'
url_list_default = 'https://www.bbiquge.net/book/133318/'
url_next = 'https://www.bbiquge.net'
pool = ThreadPoolExecutor(max_workers=50)
if __name__ =='__main__':
while True:
Htmlcode_Freetop = get_htmlcode(url_list)
novl_list = get_page_list(Htmlcode_Freetop)
for i in novl_list:
url = url_list_default + i
pool.submit(get_novel_all, url)
next_list = get_next_list(Htmlcode_Freetop)
if next_list == None:
pool.shutdown()
else:
url_list = url_next + next_list[0]
print(url_list)
|
学习即可,请不要大并发爬别人网站,造成别人服务器瘫痪跟我无关。